參考這個套件進行練習
CNN_中文二分類
https://github.com/x-hacker/CNN_ChineseTextBinaryClassify
安裝完必要套件如tensorflow
在安裝目錄下執行train.py
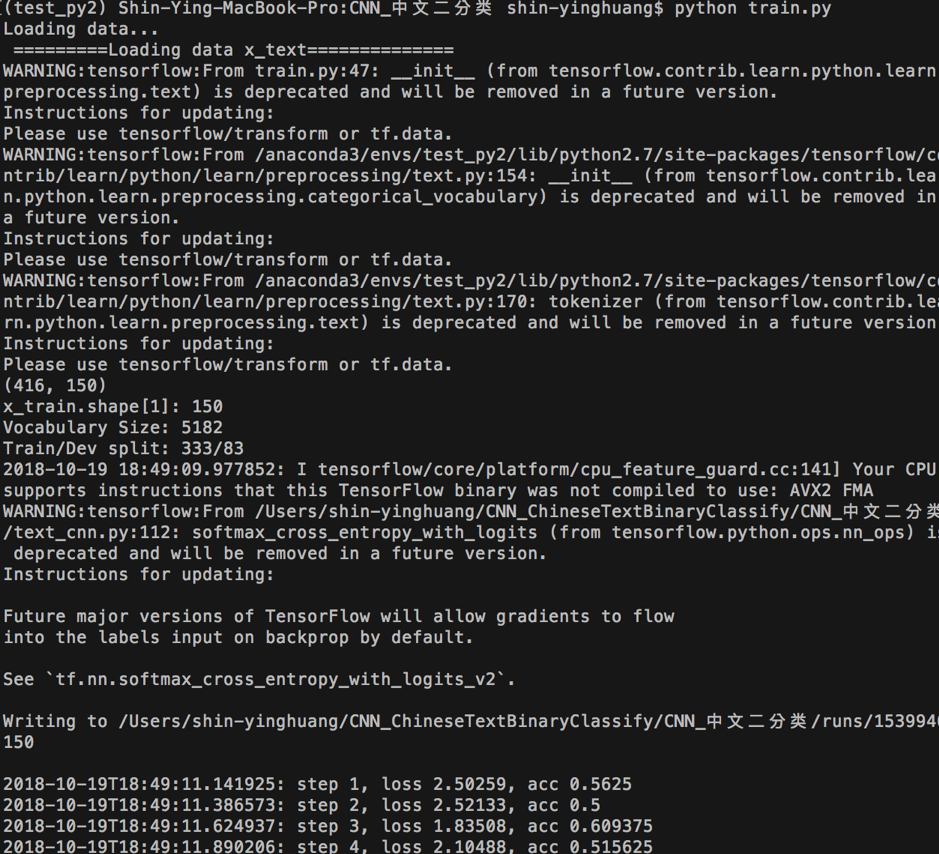
即開始訓練cnn模型
執行了大約五分鐘後得到以下結果

回到train.py的原始碼,我們來了解一下訓練資料
一個類別一個檔,這個例子是交通類別的斷詞組一個檔、交通類別的斷詞組一個檔。為了避免程式出錯,建議使用英文字檔名
tf.flags.DEFINE_float("dev_sample_percentage", .2, "Percentage of the training data to use for validation")
tf.flags.DEFINE_string("jisuanji_data_file", "./fenci/jisuanji200.txt", "Data source for the jisuanji data.")
tf.flags.DEFINE_string("jiaotong_data_file", "./fenci/jiaotong214.txt", "Data source for the jiaotong data.")
接下來看一下模型的超參數設定
#模型的超参数“:词向量的维数、过滤器的大小、每层网络上卷积核的个数、DropOut的概率、L2的参数
tf.flags.DEFINE_integer("embedding_dim", 128, "Dimensionality of character embedding (default: 128)") 詞向量維數
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')") 過濾器大小
tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)") 過濾器個數
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)") 保留比率
tf.flags.DEFINE_float("l2_reg_lambda", 0.0, "L2 regularization lambda (default: 0.0)") 正規化
訓練後的模型會儲存在時間搓記資料夾下1539946150
接下來,輸入以下指令進行模型驗證:
python eval.py --eval_train --checkpoint_dir="./runs/1539946150/checkpoints/"
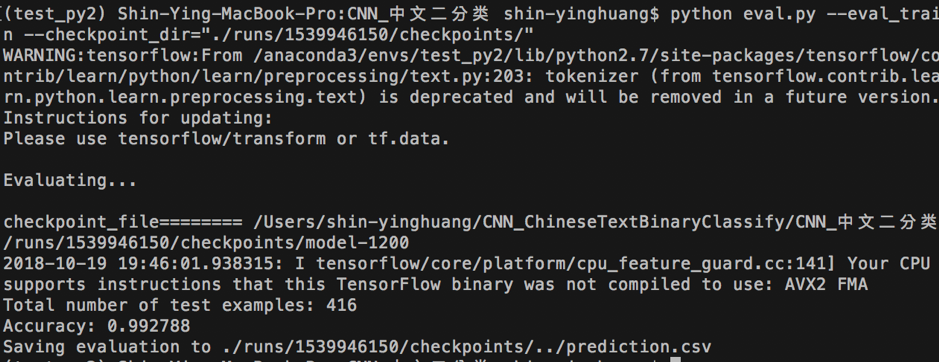
執行完後,產生prediction.csv檔案
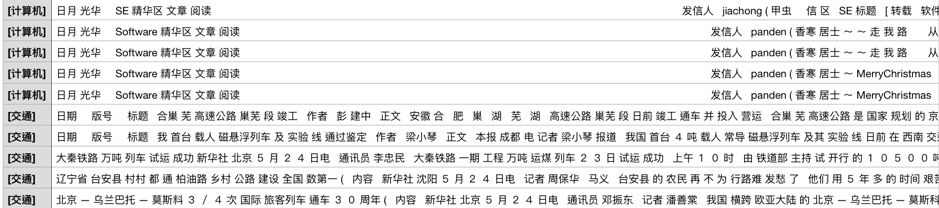
每一筆資料的開頭已加入預測標記的結果 :)

